 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Should LLMs Consume High-Quality Data? Optimal Data Scheduling via Quality-Aware Functional Scaling Laws
May 25, 2026High-quality data is scarce in large language model (LLM) training, yet how to schedule its use jointly with training dynamics lacks theoretical guidance. We extend functional scaling laws by incorporating a data-quality dimension, and solve the joint data-quality and batch-size scheduling problem in asymptotic closed form. The solution reveals two regimes and a dual role of high-quality data. In the noise-limited regime, high-quality data should be used as a signal amplifier: lowering the batch size converts cleaner data into more signal without amplifying noise. In the signal-limited regime, it should be used as a noise suppressor: late placement reduces terminal noise without sacrificing signal accumulation. Existing curriculum-style pipelines primarily exploit the second role by placing cleaner data late, but miss the first role because conventional decay schedules reduce update intensity exactly when high-quality data becomes available. Guided by this, we propose Drop-Stable-Rampup for LLM midtraining: upon the quality transition, drop the batch size, hold it stable to accumulate signal, then ramp up to suppress terminal noise. On a 15B Mixture-of-Experts model midtrained on 108B tokens, Drop-Stable-Rampup improves average accuracy over Warmup-Stable-Decay (WSD) by +1.70 and over Cosine-decay by +2.98, with particularly large gains on mathematical reasoning benchmarks such as GSM8K (+4.23) and MATH (+2.80).
Meta-LegNet: A Transferable and Interpretable Framework for Surface Adsorption Prediction via Self-Defined Adsorption-Environment Learning
May 03, 2026A central challenge in computational catalysis is the identification of low-energy and chemically plausible adsorption configurations, as these directly affect adsorption energies, reaction pathways, and catalytic performance. Existing approaches generally rely on enumerating candidate adsorption sites followed by iterative refinement through density functional theory calculations or machine-learning-based relaxations. However, such workflows remain computationally expensive and are difficult to scale to complex surfaces or multi-adsorbate systems. Here, we introduce Meta-LegNet, a graph learning framework that combines SE(3)-equivariant atom-level message passing with voxel-based multiscale aggregation and cross-domain meta-learning to learn transferable representations of local adsorption environments across diverse catalyst--adsorbate systems. Rather than following a conventional regression-only paradigm, Meta-LegNet encodes local chemical environments using invariant radial features and equivariant directional information, and further incorporates broader structural context through coordinate-frame voxel pooling, assignment-based upsampling, and gated feature fusion. The resulting local-global decomposition produces atom-resolved attribution maps, which are processed to identify adsorption-relevant local environments in an interpretable manner. Based on the learned representations, we further construct an adsorption-environment database and develop a template-matching strategy to propose likely adsorption sites on previously unexplored surfaces without exhaustive site enumeration. Overall, our results suggest that learning transferable adsorption environments provides an accurate, interpretable, and practical route for accelerating catalyst screening.
HE-SNR: Uncovering Latent Logic via Entropy for Guiding Mid-Training on SWE-BENCH
Jan 28, 2026SWE-bench has emerged as the premier benchmark for evaluating Large Language Models on complex software engineering tasks. While these capabilities are fundamentally acquired during the mid-training phase and subsequently elicited during Supervised Fine-Tuning (SFT), there remains a critical deficit in metrics capable of guiding mid-training effectively. Standard metrics such as Perplexity (PPL) are compromised by the "Long-Context Tax" and exhibit weak correlation with downstream SWE performance. In this paper, we bridge this gap by first introducing a rigorous data filtering strategy. Crucially, we propose the Entropy Compression Hypothesis, redefining intelligence not by scalar Top-1 compression, but by the capacity to structure uncertainty into Entropy-Compressed States of low orders ("reasonable hesitation"). Grounded in this fine-grained entropy analysis, we formulate a novel metric, HE-SNR (High-Entropy Signal-to-Noise Ratio). Validated on industrial-scale Mixture-of-Experts (MoE) models across varying context windows (32K/128K), our approach demonstrates superior robustness and predictive power. This work provides both the theoretical foundation and practical tools for optimizing the latent potential of LLMs in complex engineering domains.
An Automatic Detection Method for Hematoma Features in Placental Abruption Ultrasound Images Based on Few-Shot Learning
Oct 24, 2025



Placental abruption is a severe complication during pregnancy, and its early accurate diagnosis is crucial for ensuring maternal and fetal safety. Traditional ultrasound diagnostic methods heavily rely on physician experience, leading to issues such as subjective bias and diagnostic inconsistencies. This paper proposes an improved model, EH-YOLOv11n (Enhanced Hemorrhage-YOLOv11n), based on small-sample learning, aiming to achieve automatic detection of hematoma features in placental ultrasound images. The model enhances performance through multidimensional optimization: it integrates wavelet convolution and coordinate convolution to strengthen frequency and spatial feature extraction; incorporates a cascaded group attention mechanism to suppress ultrasound artifacts and occlusion interference, thereby improving bounding box localization accuracy. Experimental results demonstrate a detection accuracy of 78%, representing a 2.5% improvement over YOLOv11n and a 13.7% increase over YOLOv8. The model exhibits significant superiority in precision-recall curves, confidence scores, and occlusion scenarios. Combining high accuracy with real-time processing, this model provides a reliable solution for computer-aided diagnosis of placental abruption, holding significant clinical application value.
RoHyDR: Robust Hybrid Diffusion Recovery for Incomplete Multimodal Emotion Recognition
May 23, 2025Multimodal emotion recognition analyzes emotions by combining data from multiple sources. However, real-world noise or sensor failures often cause missing or corrupted data, creating the Incomplete Multimodal Emotion Recognition (IMER) challenge. In this paper, we propose Robust Hybrid Diffusion Recovery (RoHyDR), a novel framework that performs missing-modality recovery at unimodal, multimodal, feature, and semantic levels. For unimodal representation recovery of missing modalities, RoHyDR exploits a diffusion-based generator to generate distribution-consistent and semantically aligned representations from Gaussian noise, using available modalities as conditioning. For multimodal fusion recovery, we introduce adversarial learning to produce a realistic fused multimodal representation and recover missing semantic content. We further propose a multi-stage optimization strategy that enhances training stability and efficiency. In contrast to previous work, the hybrid diffusion and adversarial learning-based recovery mechanism in RoHyDR allows recovery of missing information in both unimodal representation and multimodal fusion, at both feature and semantic levels, effectively mitigating performance degradation caused by suboptimal optimization. Comprehensive experiments conducted on two widely used multimodal emotion recognition benchmarks demonstrate that our proposed method outperforms state-of-the-art IMER methods, achieving robust recognition performance under various missing-modality scenarios. Our code will be made publicly available upon acceptance.
SDR-Former: A Siamese Dual-Resolution Transformer for Liver Lesion Classification Using 3D Multi-Phase Imaging
Feb 27, 2024



Automated classification of liver lesions in multi-phase CT and MR scans is of clinical significance but challenging. This study proposes a novel Siamese Dual-Resolution Transformer (SDR-Former) framework, specifically designed for liver lesion classification in 3D multi-phase CT and MR imaging with varying phase counts. The proposed SDR-Former utilizes a streamlined Siamese Neural Network (SNN) to process multi-phase imaging inputs, possessing robust feature representations while maintaining computational efficiency. The weight-sharing feature of the SNN is further enriched by a hybrid Dual-Resolution Transformer (DR-Former), comprising a 3D Convolutional Neural Network (CNN) and a tailored 3D Transformer for processing high- and low-resolution images, respectively. This hybrid sub-architecture excels in capturing detailed local features and understanding global contextual information, thereby, boosting the SNN's feature extraction capabilities. Additionally, a novel Adaptive Phase Selection Module (APSM) is introduced, promoting phase-specific intercommunication and dynamically adjusting each phase's influence on the diagnostic outcome. The proposed SDR-Former framework has been validated through comprehensive experiments on two clinical datasets: a three-phase CT dataset and an eight-phase MR dataset. The experimental results affirm the efficacy of the proposed framework. To support the scientific community, we are releasing our extensive multi-phase MR dataset for liver lesion analysis to the public. This pioneering dataset, being the first publicly available multi-phase MR dataset in this field, also underpins the MICCAI LLD-MMRI Challenge. The dataset is accessible at:https://bit.ly/3IyYlgN.
Generate to Understand for Representation
Jun 14, 2023In recent years, a significant number of high-quality pretrained models have emerged, greatly impacting Natural Language Understanding (NLU), Natural Language Generation (NLG), and Text Representation tasks. Traditionally, these models are pretrained on custom domain corpora and finetuned for specific tasks, resulting in high costs related to GPU usage and labor. Unfortunately, recent trends in language modeling have shifted towards enhancing performance through scaling, further exacerbating the associated costs. Introducing GUR: a pretraining framework that combines language modeling and contrastive learning objectives in a single training step. We select similar text pairs based on their Longest Common Substring (LCS) from raw unlabeled documents and train the model using masked language modeling and unsupervised contrastive learning. The resulting model, GUR, achieves impressive results without any labeled training data, outperforming all other pretrained baselines as a retriever at the recall benchmark in a zero-shot setting. Additionally, GUR maintains its language modeling ability, as demonstrated in our ablation experiment. Our code is available at \url{https://github.com/laohur/GUR}.
Cluster Entropy: Active Domain Adaptation in Pathological Image Segmentation
Apr 26, 2023



The domain shift in pathological segmentation is an important problem, where a network trained by a source domain (collected at a specific hospital) does not work well in the target domain (from different hospitals) due to the different image features. Due to the problems of class imbalance and different class prior of pathology, typical unsupervised domain adaptation methods do not work well by aligning the distribution of source domain and target domain. In this paper, we propose a cluster entropy for selecting an effective whole slide image (WSI) that is used for semi-supervised domain adaptation. This approach can measure how the image features of the WSI cover the entire distribution of the target domain by calculating the entropy of each cluster and can significantly improve the performance of domain adaptation. Our approach achieved competitive results against the prior arts on datasets collected from two hospitals.
Mixing Data Augmentation with Preserving Foreground Regions in Medical Image Segmentation
Apr 26, 2023



The development of medical image segmentation using deep learning can significantly support doctors' diagnoses. Deep learning needs large amounts of data for training, which also requires data augmentation to extend diversity for preventing overfitting. However, the existing methods for data augmentation of medical image segmentation are mainly based on models which need to update parameters and cost extra computing resources. We proposed data augmentation methods designed to train a high accuracy deep learning network for medical image segmentation. The proposed data augmentation approaches are called KeepMask and KeepMix, which can create medical images by better identifying the boundary of the organ with no more parameters. Our methods achieved better performance and obtained more precise boundaries for medical image segmentation on datasets. The dice coefficient of our methods achieved 94.15% (3.04% higher than baseline) on CHAOS and 74.70% (5.25% higher than baseline) on MSD spleen with Unet.
Compound Domain Generalization via Meta-Knowledge Encoding
Mar 24, 2022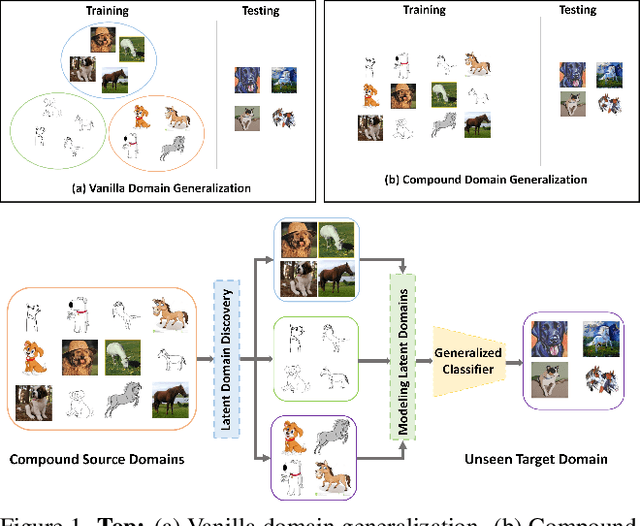
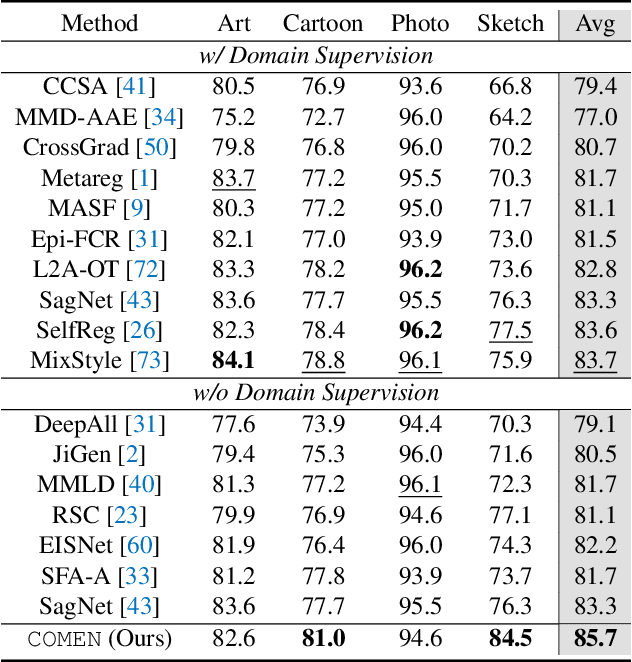
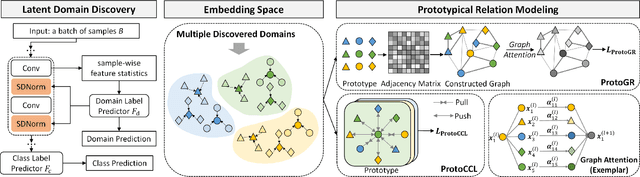
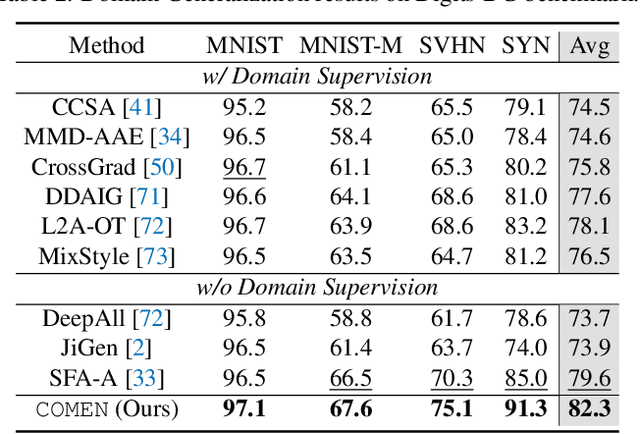
Domain generalization (DG) aims to improve the generalization performance for an unseen target domain by using the knowledge of multiple seen source domains. Mainstream DG methods typically assume that the domain label of each source sample is known a priori, which is challenged to be satisfied in many real-world applications. In this paper, we study a practical problem of compound DG, which relaxes the discrete domain assumption to the mixed source domains setting. On the other hand, current DG algorithms prioritize the focus on semantic invariance across domains (one-vs-one), while paying less attention to the holistic semantic structure (many-vs-many). Such holistic semantic structure, referred to as meta-knowledge here, is crucial for learning generalizable representations. To this end, we present Compound Domain Generalization via Meta-Knowledge Encoding (COMEN), a general approach to automatically discover and model latent domains in two steps. Firstly, we introduce Style-induced Domain-specific Normalization (SDNorm) to re-normalize the multi-modal underlying distributions, thereby dividing the mixture of source domains into latent clusters. Secondly, we harness the prototype representations, the centroids of classes, to perform relational modeling in the embedding space with two parallel and complementary modules, which explicitly encode the semantic structure for the out-of-distribution generalization. Experiments on four standard DG benchmarks reveal that COMEN exceeds the state-of-the-art performance without the need of domain supervision.